Self Supervised Learning: What It's, Why Significant , How it Works, Types, Applications, Advantages, Disadvantages and Strategies ! Add Value to Your Innovation with AI !!

Abstract:
Self-supervised learning (SSL) is a machine learning technique that uses unlabeled data to train a model to predict parts of the data. Here are some key points about SSL:
How it works
SSL uses unlabeled data to generate fake labels, which are then used to train a model. The model learns to predict parts of the data from other parts, including incomplete, distorted, or corrupted fragments.
How it's used
SSL is commonly used to solve computer vision problems like object detection, image classification, and semantic segmentation.
Why it's useful
SSL is considered a promising way to build machines with basic knowledge, or "common sense". It's also useful when labeled data is expensive to obtain.
How it's different from other learning methods
SSL is different from supervised learning, which requires labeled data, and unsupervised learning, which doesn't provide explicit feedback. SSL is considered a bridge between supervised and unsupervised learning because it uses more feedback signals than supervised and reinforcement learning, but it's not truly unsupervised.
How it's used in NLP
In natural language processing (NLP), SSL can be used to learn the basic style of text and predict the next word in a sentence. The model can then be fine-tuned for downstream tasks like sentiment analysis or text classification.
Keywords:
Self-supervised learning (SSL), Sentiment analysis, Text classification. Object detection, Image classification, and Semantic segmentation.
Learning Outcomes
After undergoing this article you will be able to understand the following:
1. What's Self Supervised Learning?
2. Why is Self Supervised Learning is important?
3. What are the objectives of Self Supervised Learning?
4. How Self Supervised Learning works?
5. What are the types of Self Supervised Learning?
6. What's the features and Characteristics of Self Supervised Learning?
7. What's the applications of Self Supervised Learning?
8. Advantages of Self Supervised Learning
9. Disadvantages of Self Supervised Learning
10. Trends of Self Supervised Learning
11. Evolving Techniques of Self Supervised Learning
12. Top strategies to succeed in application of Self Supervised Learning
13. Conclusions
14. FAQs
References
1. What's Self Supervised Learning?
Self-supervised learning (SSL) is a machine learning technique that uses unsupervised learning to perform tasks that usually require supervised learning. SSL is useful in fields like computer vision and natural language processing (NLP).
Here's how SSL works:
Masking: A part of the training data is masked.
Training: The model is trained to identify the hidden data.
Analyzing: The structure and characteristics of the unmasked data are analyzed.
Using labeled data: The labeled data is used for the supervised learning stage.
SSL is also known as predictive or pretext learning. It's considered a promising way to build machines with basic knowledge, or "common sense".
Here are some things to know about SSL:
SSL models generate their own labels for the dataset, so they may not be as accurate as traditional supervised learning models.
Contrastive Predictive Coding (CPC) is a popular approach to SSL in NLP, computer vision, and deep learning.
SSL has found practical application in audio processing and is being used by Facebook and others for speech recognition.
2. Why is Self Supervised Learning is important?
Self-supervised learning (SSL) is a computer science technique that's important for AI systems because it can:
Learn from more data
SSL can help AI systems learn from large amounts of data, which is important for understanding patterns.
Be more cost-effective
SSL can be more cost-effective than supervised learning because it reduces the need for manual labeling of training data.
Be more scalable
SSL can handle large datasets, making it suitable for real-world applications.
Be more flexible
SSL is adaptable to a wide variety of tasks and domains.
Be more generalizable
When trained on enough raw data, SSL models can learn to perform new tasks.
Help build common sense
SSL is a promising way to build basic knowledge and common sense in AI systems.
SSL works by using unannotated data to generate fake labels, which are then used to train a model. This allows the model to learn and extract meaningful features from the data without the need for manual annotation.
3. What are the objectives of Self Supervised Learning?
Self-supervised learning has several objectives, including:
Reducing the need for labeled data
Self-supervised learning aims to reduce or eliminate the need for labeled data, which is expensive and scarce, by using unlabeled data instead.
Generalization
Models trained using self-supervised learning can perform new tasks, even if they weren't trained on directly relevant data. This is because they learn more robust features from the data.
Scalability
Self-supervised learning can handle large datasets, making it suitable for real-world applications where labeled data is limited.
Flexibility
Self-supervised learning is adaptable to a wide variety of tasks and domains.
Learning general features
Self-supervised learning learns general features through solving pretext tasks.
4. How Self Supervised Learning works?
Self-supervised learning is a computer science technique that uses unlabeled data to train models by generating artificial labels. It works by:
Masking data: The model is trained to identify hidden data by masking part of the training data.
Analyzing structure: The model analyzes the structure and characteristics of the unmasked data.
Generating labels: The model generates labels for the hidden data.
Using labels: The model uses the generated labels to train itself like a supervised learning model.
Self-supervised learning is a combination of supervised and unsupervised learning. It's most often used to solve computer vision problems, such as image classification, object detection, and semantic segmentation. Here are some advantages of self-supervised learning:
No manual annotation
Self-supervised learning allows models to learn from data without manual annotation.
More feedback signals
Self-supervised learning uses more feedback signals than supervised and reinforcement learning methods.
Image augmentation
Newer methods use image augmentation to train models to find pairs of images that belong to the same original image.
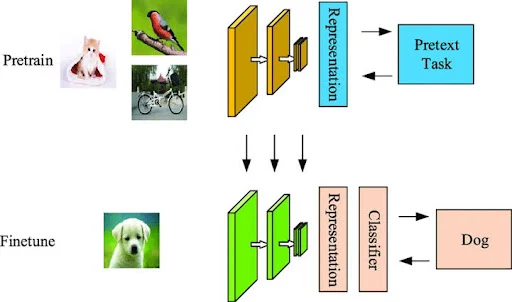
5. What are the types of Self Supervised Learning?
Here are some types of self-supervised learning:
Self-predictive learning
This technique uses autoencoding to compress information into a simpler form and then recreate the original data.
Contrastive learning
This technique compares images in pairs or groups to teach the model how to distinguish between similar and different images.
Clustering-based methods
This technique groups similar data points together and uses these clusters as pseudo-labels for training.
Pretext task
This task is used to learn visual representations, which can then be used for other tasks.
Self-supervised learning is a type of unsupervised learning that uses data to train a pretext task. This helps the learning algorithm to identify the underlying patterns in the data. It can be used to perform computer vision tasks like image comprehension, image segmentation, and object detection.
6. What's the features and Characteristics of Self Supervised Learning?
Self-supervised learning is a machine learning technique where a model learns representations from unlabeled data by creating its own "labels" through data transformations, essentially predicting parts of the data from other parts, allowing it to extract meaningful features without needing human-annotated labels; key characteristics include:
Generating labels from data:
The model generates its own supervisory signals by manipulating the input data (e.g., cropping, rotating, adding noise) and then predicting the original or missing parts, effectively creating "pseudo-labels" from the unlabeled data.
No manual annotation required:
Unlike supervised learning, self-supervised learning does not rely on pre-labeled data, making it ideal for scenarios where labeled data is scarce or expensive to acquire.
Pretext tasks:
The process of generating pseudo-labels often involves a "pretext task" where the model is asked to predict a specific aspect of the data, like identifying the masked part of an image or reconstructing a corrupted signal.
Feature extraction:
The main goal of self-supervised learning is to learn robust feature representations from the data that can be later used for downstream tasks like classification or object detection, even when labeled data is limited.
Data augmentation techniques:
To create diverse "pseudo-labels", self-supervised learning often leverages data augmentation techniques like cropping, resizing, color jittering, and other transformations.
Scalability with large datasets:
Since it doesn't require manual labeling, self-supervised learning can easily scale to massive datasets.
Bridging supervised and unsupervised learning:
Self-supervised learning is often considered a bridge between supervised and unsupervised learning, as it utilizes unlabeled data to generate pseudo-labels that can then be used for supervised training.
Applications in computer vision and NLP:
Self-supervised learning is particularly useful in computer vision tasks like image classification and object detection, as well as natural language processing applications where large amounts of unlabeled text data are available.
7. What's the applications of Self Supervised Learning?
Self-supervised learning (SSL) has many applications, including:
Computer vision
SSL can improve image and video analysis by teaching models to understand images and videos without labeled datasets. For example, a model can learn to identify objects in an image by looking at the surrounding pixels.
Natural language processing (NLP)
SSL can help models understand and generate human language. For example, models like BERT and GPT-3 use SSL for chatbots, translation, and text summarization.
Speech recognition
SSL can improve speech recognition systems by learning from large amounts of unlabeled audio data.
Healthcare
SSL can help identify important features in medical images like X-rays, CT scans, and MRIs without the need for labels.
Reinforcement learning
SSL can help AI agents generalize their knowledge across different games and situations. For example, SSL has been used to improve performance in Atari games.
Improving supervised learning models
SSL can improve the performance of supervised learning models by pretraining on large amounts of unlabeled data. This is especially useful when labeled data is scarce or expensive to obtain.
8. Advantages of Semi Supervised Learning
Semi-supervised learning has many advantages, including:
Improved predictions
Semi-supervised learning can provide better prediction quality than supervised learning because it uses both labeled and unlabeled data.
Cost-effectiveness
Semi-supervised learning reduces the need for labeling data, which can be time-consuming and expensive.
Versatility
Semi-supervised learning can be used in many applications, including image classification, sentiment analysis, and spam filtering.
Handles diverse data
Semi-supervised learning can work with different types of data, such as images, text, and sensor data.
Improved clustering
Semi-supervised learning can identify and understand complex patterns, which can lead to better clustering and classification.
Handles rare classes
Semi-supervised learning can effectively manage rare classes in datasets.
Natural language processing
Semi-supervised learning can help models learn contextual representations from unlabeled text data.
Semi-supervised learning combines supervised and unsupervised learning techniques. It works by training an initial model on a small amount of labeled data, and then applying it to a larger amount of unlabeled data.
9. Disadvantages of Self Supervised Learning
Self-supervised learning (SSL) has a few disadvantages, including:
Computational power
SSL requires large amounts of computational power and time to train models, especially on large datasets.
Low accuracy
SSL models may not produce results as accurate as other approaches because they don't receive human input in the form of labels or annotations.
Noise sensitivity
Pseudo-labels generated from raw data can be irrelevant to the goal, which can negatively impact performance.
Bias amplification
SSL models can learn and amplify biases that are already present in the data, leading to skewed or unfair outcomes.
Complexity
Creating effective pretext tasks and generating pseudo-labels requires careful design and experimentation.
Error during labeling
When using SSL with unlabeled datasets, errors can occur during manual labeling, which can lead to inaccurate results.
SSL is a useful technique in fields such as natural language processing and computer vision. It generates implicit labels from unstructured data instead of relying on labeled datasets.
10. Developments in Self Supervised Learning
Self-supervised learning (SSL) is a type of machine learning that has seen rapid development in recent years. Here are some developments in SSL:
Improved accuracy
Between late 2019 and early 2021, the accuracy of SSL models increased dramatically.
Dinov2
This SSL model is based on the Vision Transformer (ViT) architecture. It can be used to screen for helminth egg infections.
Pretraining
SSL can be used to pretrain supervised learning models on large amounts of unlabeled data. This can improve the performance of supervised learning models, especially when labeled data is scarce or expensive.
Natural language processing
SSL is used in natural language processing, and has been used in GPT-3 and BERT.
Computer vision
SSL performs well in computer vision, and can be used for tasks like image classification, object detection, and semantic segmentation.
Colorization
SSL can be used to automatically colorize grayscale images or videos.
Image inpainting
SSL can be used for image inpainting.
Context filling
SSL can be used for context filling, such as text prediction or predicting gaps in voice recordings.
11. Techniques of Self Supervised Learning
Here are some techniques for self-supervised learning:
Contrastive learning
A popular method for self-supervised learning that allows for training models without labeled data. It trains encoders to learn from large amounts of unlabeled data.
Transfer learning
A model is pre-trained on large unlabeled text corpora using self-supervised learning. It is then minimally adjusted during fine-tuning on a specific NLP task.
Clustering
A method for grouping similar data points together. It can be used as a self-supervised learning method by training a model to predict the cluster assignments of data points.
Pretext task
A self-supervised learning task that learns visual representations. The learned representations or model weights can be used for other downstream tasks.
Bootstrap Your Own Latent (BYOL)
An approach for image representation that trains an online network to predict a target network representation of a different augmented view of the same image.
Self-supervised learning is a type of unsupervised learning where the label, or supervisory signal, comes from the data itself. It's a semi-supervised machine learning technique that frames the problem as a supervised learning task to generate labeled data from unlabeled data.
12. Strategies for Self Supervised Learning
Some strategies for self-supervised learning include:
Contrastive learning
A method for training encoders to learn from unlabeled data by using the data itself as the supervisory signal or label.
Pretext tasks
A self-supervised learning task that uses a property of the dataset to learn visual representations. The learned representations can then be used for other tasks.
Clustering
A method for grouping similar data points together. A model can be trained to predict the cluster assignments of data points.
Smart pre-training task design
A strategy for solving data labeling problems that are time-consuming and labor-intensive.
Encouraging networks to capture high-level semantics
A strategy for designing pretext tasks to encourage networks to learn semantically useful representations from unlabeled data.
Self-supervised learning (SSL) is an unsupervised training paradigm that mines effective information from the data itself.
13. Conclusions
14. FAQs
References
Comments
Post a Comment
"Thank you for seeking advice on your career journey! Our team is dedicated to providing personalized guidance on education and success. Please share your specific questions or concerns, and we'll assist you in navigating the path to a fulfilling and successful career."